Training Machine Learning to Anticipate Manipulation
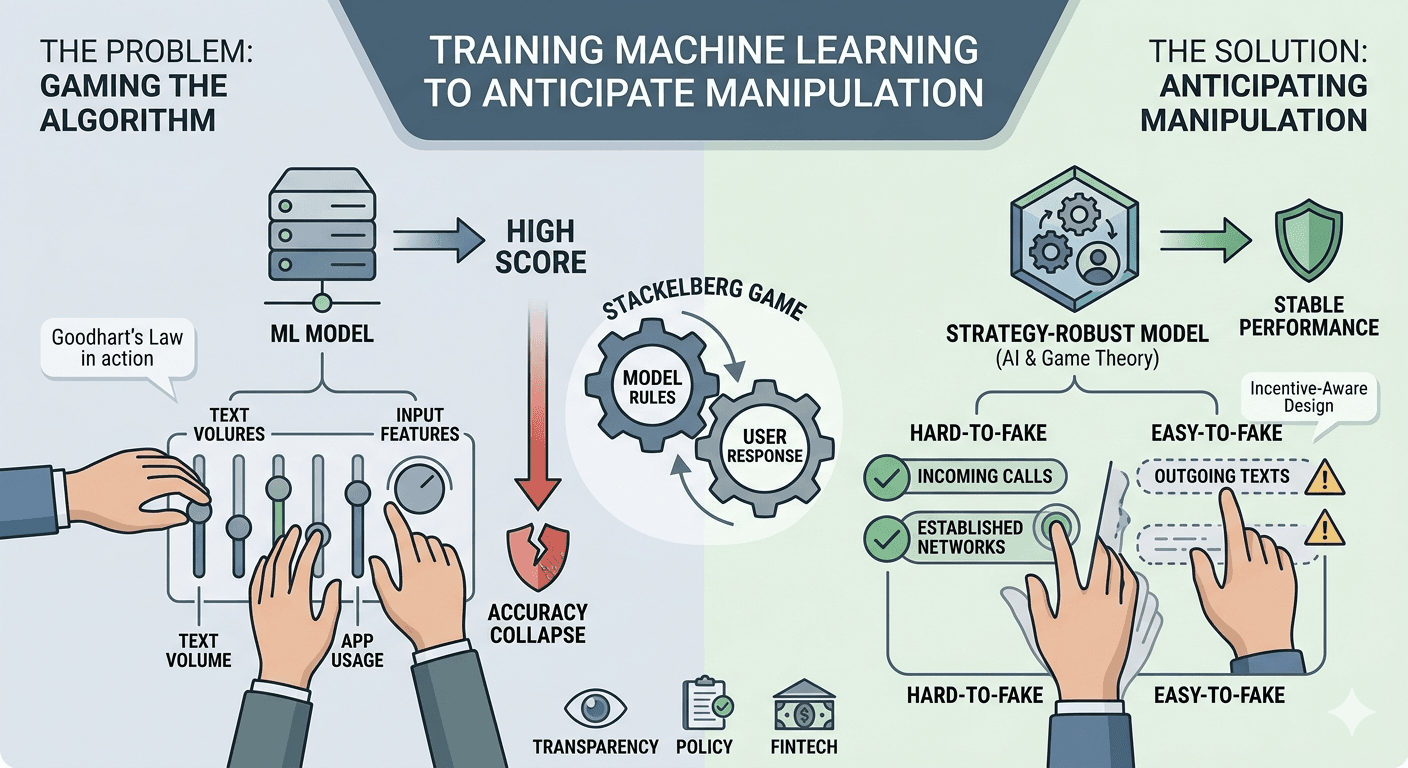
The paper “Training Machine Learning to Anticipate Manipulation” (Blumenstock et al., 2023) addresses a fundamental flaw in standard machine learning: the assumption that data distributions remain stable when models are deployed. In reality, when algorithms make consequential decisions—such as awarding loans or granting parole—individuals have strong incentives to “game” the system by strategically altering their behavior (Björkegren et al., 2023).
The Core Problem: Strategic Manipulation
Standard machine learning models are trained to maximize “fit” on historical data. However, once a decision rule is made public or its logic becomes apparent, users may change the very features the model relies on (e.g., sending more text messages to appear more “active” for a credit score). This phenomenon, often referred to as Goodhart’s Law, can cause a model’s predictive accuracy to collapse upon deployment (Björkegren et al., 2023).
The Solution: Strategy-Robust Decision Rules
The authors propose an empirical approach that integrates an economic model of human behavior directly into the machine learning estimator. Instead of just looking at historical correlations, this “strategy-robust” approach:
Models Incentives: It explicitly accounts for the cost an individual faces to manipulate specific behaviors (Björkegren et al., 2023).
Anticipates Responses: It embeds a game-theoretic model within the loss function, allowing the algorithm to predict how individuals will adjust their $x$ (features) in response to a rule $pi$ (Björkegren et al., 2023).
Prioritizes “Hard-to-Fake” Signals: The model learns to assign higher weights to features that are costly or difficult to manipulate, while de-emphasizing easily “gamed” behaviors (Björkegren et al., 2023).
Real-World Evidence: The Kenya Field Experiment
To validate their theory, the researchers conducted a large-scale field experiment in Kenya involving a smartphone-based “digital credit” app.
Experimental Design: Participants were incentivized to manipulate their phone usage (e.g., number of outgoing calls or texts) to qualify for cash rewards, mimicking the incentives of digital loans (Blumenstock et al., 2023).
Key Findings:
Predictability of Manipulation: The study found that behaviors like “outgoing communications” are significantly easier and cheaper to manipulate than “incoming communications” (Blumenstock et al., 2023).
Performance: The strategy-robust estimator produced decision rules that were stable even when fully transparent. It outperformed standard OLS models, which failed when users began strategically altering their data (Björkegren et al., 2023).
The Signaling Effect: Interestingly, the authors noted that if the ability to manipulate a feature is itself correlated with the desired outcome (e.g., highly “intelligent” people are better at gaming a specific test), the model can actually exploit this as a signal (Björkegren et al., 2023).
Why It Matters
This research challenges the “security through obscurity” approach, where algorithms are kept secret to prevent gaming. By making models robust to manipulation, policymakers can provide the “right to explanation” and transparency demanded by modern AI regulations without sacrificing the integrity of the decision-making process (Björkegren et al., 2023).
Read full paper on https://www.povertyactionlab.org/sites/default/files/research-paper/WP4644_Training-Machine-Learning-to-Anticipate-Manipulation-in-Kenya_Blumenstock-et-al_July2023.pdf