
Building an Enterprise-Grade Cloud Architecture for Generative AI Models
Generative AI (GenAI) has fundamentally disrupted how organizations approach artificial intelligence, business solution development, and daily operational workflows. Capable of generating novel content such as text, images, audio, video, code, and sophisticated simulations, GenAI is driving powerful innovations across diverse sectors. Deep learning algorithms and neural networks power these capabilities by recognizing complex patterns in extensive datasets, relying heavily on mechanisms like attention techniques to understand precisely where to focus when creating new outputs.
However, running these deep learning models requires enormous computational power, high-speed network bandwidth, and voluminous storage. Because enterprise cloud platforms provide on-demand, highly scalable, and AI-optimized computing resources via a flexible pay-as-you-go model, they serve as the ideal foundation for developing, training, testing, and deploying GenAI models securely and sustainably.
The Generative AI Lifecycle: Training vs. Adaptation
Architecting for GenAI begins with understanding the distinct phases of model deployment, which differ substantially from traditional, task-specific machine learning workflows.
Training Foundation Models (FMs): FMs are pre-trained on massive, unlabelled datasets to perform highly versatile tasks. This compute-intensive phase involves raw data cleaning, pre-processing, defining structural layers, and fine-tuning parameters over extensive processing runs.
Adapting Existing FMs: Rather than gathering labeled data from scratch to build custom models, organizations can adapt pre-trained FMs to specialized domains via techniques like targeted fine-tuning or Retrieval-Augmented Generation (RAG). This approach requires only a fraction of the data and computing resources compared to training an end-to-end model.
Choosing the Right Cloud Service Delivery Model
Enterprises must decide how to provision and host their underlying infrastructure based on strict governance, cost, and operational preferences:
On-Premises: The customer retains end-to-end management and ownership over all physical hardware, networks, servers, operating systems, applications, and data. While offering complete physical control, this places the heavy burden of infrastructure maintenance directly on the internal organization.
Infrastructure as a Service (IaaS): Organizations rent virtualized compute, storage, and networking resources. This grants complete flexibility over underlying runtimes, operating systems, and middleware, enabling highly custom deployments on platforms like AWS, Azure, or Google Cloud.
Platform as a Service (PaaS): Cloud providers manage and optimize the underlying computing environment, allowing data scientists to focus exclusively on hosted applications and enterprise datasets. A common example includes serverless AI provisioning environments.
Software as a Service (SaaS): Rented on a convenient subscription basis, pre-trained platforms allow developers to seamlessly integrate GenAI functionalities directly into enterprise portals via standard application programming interfaces (APIs).
Core Components of an Enterprise Reference Architecture
Building an effective, production-ready GenAI platform requires a highly layered, decoupled architectural blueprint.
Data Processing Layer: Handles the secure ingestion, cleaning, normalization, and feature extraction of unlabelled, semi-structured, and unstructured enterprise datasets. Unprocessed data typically lands in a highly scalable data lake before being transformed into a structured data warehouse for direct utilization.
Generative Model Layer: Responsible for model selection, training, fine-tuning, and generating novel outputs using underlying machine learning frameworks.
Deployment, Integration & API Layer: Connects the core GenAI models to front-end channels such as web portals, mobile applications, or internal tools. Incoming traffic passes through an application load balancer to distributed, containerized web applications fronted by an API Gateway. The API Gateway exposes standardized endpoints while securely abstracting underlying serverless functions or backend model endpoints.
Feedback, Monitoring & Maintenance Layer: Provides continuous system observability, log analysis, automated scaling, and continuous resource updates. Real-world interaction data feeds back into extract, transform, and load (ETL) pipelines to continuously refine and improve model accuracy.
Secure & Highly Available Network Isolation
To guarantee security, reliability, and operational excellence, cloud hosting architectures isolate backend AI resources using strict, logical network boundaries.
Virtual Private Cloud (VPC) Isolation: Hosting applications and model endpoints within a regional VPC ensures secure, logical isolation from the open internet.
Subnet Segregation: Implementations should systematically split resources into distinct public and private subnets. Public subnets reference an internet gateway to expose external-facing resources like load balancers and client-facing APIs safely. Conversely, private application subnets host sensitive model adaptation processes, high-performance compute instances, and database stores, keeping them entirely inaccessible from outside traffic.
Egress-Only Routing: To allow isolated backend instances to download necessary software updates and security patches safely, private subnets utilize dedicated Network Address Translation (NAT) gateways to manage outward internet traffic.
Cloud Provider Ecosystems & Dedicated Accelerators
Major cloud platforms provide mature, managed ecosystems alongside specialized hardware to drive down the total cost of ownership (TCO) and reduce inference overhead.
Managed Model Platforms: Platforms like Amazon Bedrock provide fully managed access to foundational models via unified serverless APIs, while Amazon SageMaker and Google Cloud AI Platform provide comprehensive platforms to build, tune, and host custom algorithms. Azure similarly supports enterprise-grade lifecycles via Azure Machine Learning and the Azure OpenAI Service.
Dedicated Silicon Accelerators: Executing complex algorithms like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and autoregressive transformers demands massive parallel computing capabilities. Cloud-specific silicon—such as AWS Trainium for highly efficient model training, AWS Inferentia for cost-effective inference instances, and Google Cloud TPUs for low-latency processing—significantly mitigates heavy hardware costs.
Developer Augmentation: Enterprises can accelerate internal application builds using AI-powered coding companions like Amazon CodeWhisperer to generate functional snippets rapidly and scan codebases for security vulnerabilities.
Embracing the Well-Architected Framework
Enterprise GenAI solutions must strictly adhere to established cloud design principles to minimize operational and financial risks:
Security & Defense in Depth: Implement robust protections across every single layer using Identity and Access Management (IAM), Web Application Firewalls (WAF), role-based access policies, and explicit permission boundaries. Data must remain strictly encrypted both in transit via Transport Layer Security (TLS) and at rest.
Reliability & Automation: Systems must scale dynamically to handle unpredictable, spiky inference traffic. Adopting a modular microservices architecture prevents widespread outages by minimizing the blast radius of single-component failures. Furthermore, defining infrastructure via Infrastructure as Code (IaC) tools like Terraform or AWS CloudFormation ensures consistent, repeatable, and error-free deployments.
Performance Efficiency: Utilizing serverless data stores, managed model agents, and AI-optimized hardware allows engineering teams to bypass manual infrastructure administration and focus fully on application logic and end-user experiences.
Cost Optimization: Because generative workloads can incur massive expenses, enterprises must enforce strict consumption models that pay exclusively for active computing time, paired with continuous expenditure attribution to measure ROI accurately.
Emerging Frontiers: Edge Computing vs. Chiplet Clouds
As models grow exponentially in parameter volume, cloud architectures are continuously evolving to overcome physical constraints.
Edge Computing: Pushing compute closer to end-users at the network edge drastically reduces data transmission latency and centralized server bottlenecks. However, edge servers face significant physical hurdles when attempting to handle the vast memory and power requirements of growing model parameters.
Chiplet Clouds: To counter the slowdown of Moore’s Law, modern research proposes building AI supercomputers via “Chiplet clouds”. By fitting all model parameters directly inside the on-chip SRAMs of collaborative chipset modules, this highly parallel architecture eliminates traditional bandwidth limits and optimizes the overall TCO per generated token.
More reading https://drive.google.com/file/d/1GdUI57Xb_qBL53M3FKBIQnlJ35F3hZPT/view?usp=sharing

The Experimentation Edge: Driving Digital Product Innovation
In the digital age, the difference between market leaders and those left behind often comes down to one thing: how quickly they can learn. Companies like Apple, Netflix, and Amazon have disrupted entire industries by treating their business plans as sets of hypotheses to be tested rather than fixed blueprints.
Redefining the Digital Product
To understand digital innovation, we must first define what a digital product is. Unlike traditional physical goods, a digital product is a tool or platform that can be created once and sold many times. This scalability is supported by a “Digital Stack” that differs from traditional business stacks in its technical and organizational flexibility.
While physical industries like construction and healthcare face more hurdles, they are increasingly adopting digital foundations through:
- Digital Twins: Creating virtual environments to build and test equipment before physical production.
- Digital Threads: Building communication frameworks that connect product data throughout its entire lifecycle.
What is Experimentation in Business?
Experimentation is more than just trying new things. It is a structured process of determining the consequences of novel dependencies among variables like customers, partners, and competitors. In a product context, experiments aim to validate hypotheses to improve speed, lower costs, or increase revenue.
Common Testing Methods:
- A/B Testing: A controlled experiment comparing two variants, A and B.
- Multivariate Testing: Testing more than two versions simultaneously to understand complex interactions.
The BEC Process: A Framework for Learning
The paper outlines a systematic approach to experimentation known as the BEC Process:
- Identify Desired Outcome: For example, increasing long-term revenue.
- State Association: Define the design variables (x) you want to change, such as font size.
- Map to Associative Thread: Since long-term revenue is hard to measure quickly, identify a proxy variable (y), like “Dwell Time”.
- Test Association: Set up the experiment to gather data.
- Update & Analyze: Use the results to update your knowledge base and operational choices.
Design for Experimentation
Not all products are built to be tested. To drive innovation, digital products must be designed with certain principles in mind:
- Agile Development: Requirements and solutions should evolve through collaborative, cross-functional efforts.
- Modularity: Decomposing a design into smaller “modules” makes it easier to run small-loop experiments and counter the challenges of large-scale changes.
- Refactoring vs. Recomposition: Refactoring rearranges code to improve structure without changing behavior. Recomposition involves minimal behavior changes to support large-scale design shifts.
The “Countermeasure Mentality”
Innovation is not a one-time event. Inspired by the Toyota case study, successful experimenters adopt a countermeasure mentality. This means viewing every intervention as a short-term part of a continuous process of change and improvement.
In business experimentation, where total control is rarely possible, the goal isn’t necessarily to establish perfect causal relations but to find strong correlations that lead to better decision-making.
Full document can be read on https://drive.google.com/file/d/1kfZBrDMog-VlbcO_TflXhp-izYvJPKxY/view?usp=drive_link

An Investigation of ‘Sponsorship’ among Female University Students in Nairobi
Beyond the Taboo: Understanding “Sponsorship” Among Nairobi’s Students
In the bustling streets of Nairobi, the term “Sponsor” has moved beyond corporate funding into a complex social phenomenon. To many, it describes an older, wealthy man who provides financial support to a younger woman—often a university student—in exchange for companionship or sexual favors.
But what drives this culture? Is it merely a quest for luxury, or is there a deeper economic reality at play? Drawing from research by the Busara Center for Behavioral Economics and reporting by the BBC, we take a closer look at the nuances of “sugar dating” in Kenya.
More Than Just “Luxury”
While social media often portrays “sponsorship” as a shortcut to designer bags and high-end champagne, Busara’s investigation reveals a more pragmatic side. For many female students, these relationships are a survival strategy.
In an environment where the cost of living is skyrocketing and youth unemployment remains high, “sponsors” often fill the gap left by inadequate student loans and struggling families. The money isn’t always for “wants”; it’s frequently for “needs”—tuition fees, rent, and basic upkeep.
The Power Imbalance and Risks
The BBC’s coverage of the phenomenon highlights the darker side of these transactional relationships. When a relationship is built entirely on a financial contract, the power dynamic is inherently skewed. This imbalance often leaves young women vulnerable to:
Health Risks: Increased exposure to STIs and HIV due to the difficulty of negotiating safe sex with a benefactor.
Physical Safety: Reports of violence or emotional abuse when the “sponsee” attempts to exert independence.
Social Stigma: Despite its prevalence, “sponsorship” carries a heavy social cost, often isolating students from their peers or families.
A Behavioral Perspective
Busara’s research delves into the behavioral drivers, noting that the “Sponsor” culture is a symptom of broader systemic issues. It isn’t just about individual choices; it’s about a society where “transactional sex” has become normalized as a form of social mobility.
The study suggests that many students view these arrangements through a lens of “mental accounting”—separating their romantic lives from these “functional” relationships to cope with the moral or social friction involved.
The Bottom Line
“Sponsorship” in Nairobi is a complex intersection of poverty, gender inequality, and the pressure to maintain a certain lifestyle in the digital age. Understanding it requires moving past moral judgment and addressing the economic vulnerabilities that make such arrangements an attractive—or necessary—option for young women.
To truly address the risks associated with sugar dating, we must look at the root causes: economic empowerment for youth, better financial support for students, and a shift in the societal structures that equate a woman’s value with her proximity to wealth.
For more in-depth insights, you can read the original Busara Center blog here and the BBC’s investigative report here.
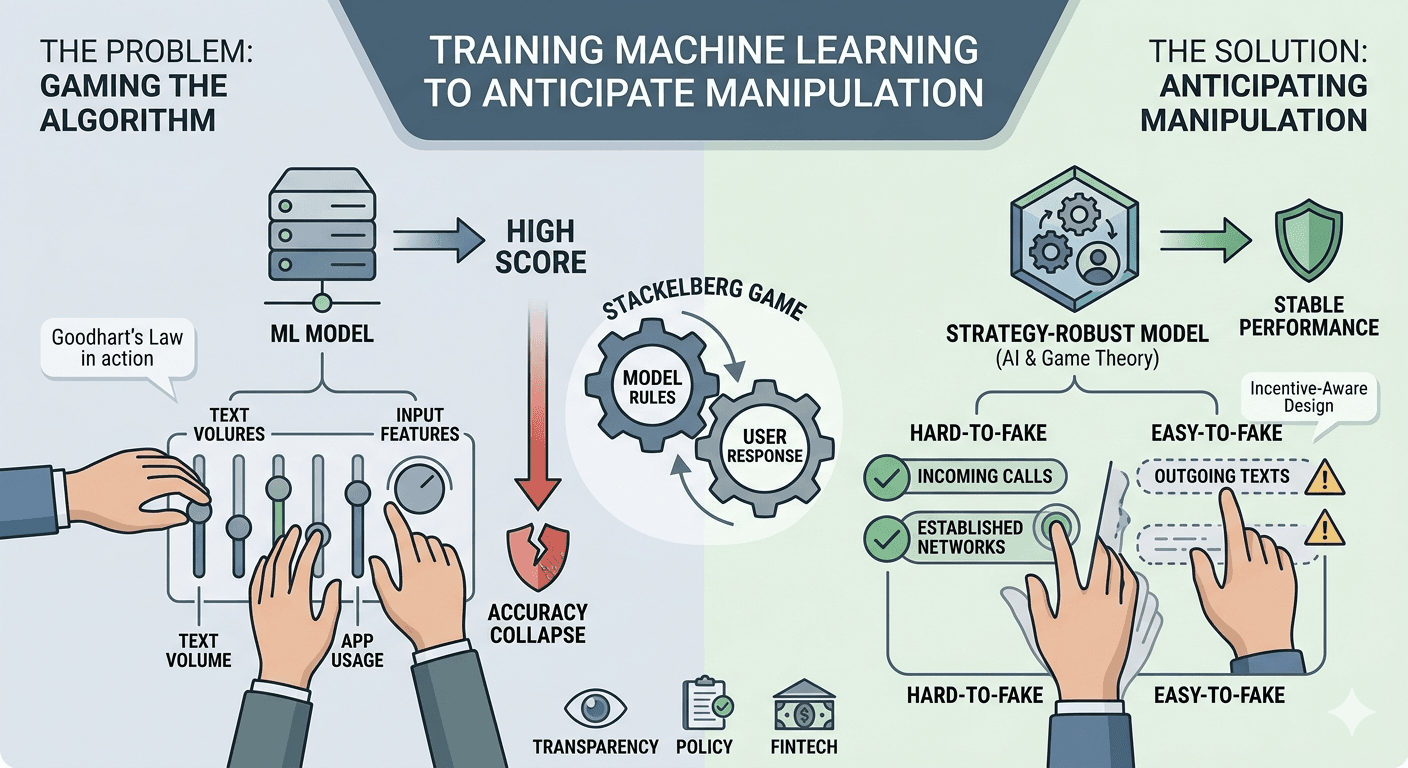
Training Machine Learning to Anticipate Manipulation
The paper “Training Machine Learning to Anticipate Manipulation” (Blumenstock et al., 2023) addresses a fundamental flaw in standard machine learning: the assumption that data distributions remain stable when models are deployed. In reality, when algorithms make consequential decisions—such as awarding loans or granting parole—individuals have strong incentives to “game” the system by strategically altering their behavior (Björkegren et al., 2023).
The Core Problem: Strategic Manipulation
Standard machine learning models are trained to maximize “fit” on historical data. However, once a decision rule is made public or its logic becomes apparent, users may change the very features the model relies on (e.g., sending more text messages to appear more “active” for a credit score). This phenomenon, often referred to as Goodhart’s Law, can cause a model’s predictive accuracy to collapse upon deployment (Björkegren et al., 2023).
The Solution: Strategy-Robust Decision Rules
The authors propose an empirical approach that integrates an economic model of human behavior directly into the machine learning estimator. Instead of just looking at historical correlations, this “strategy-robust” approach:
Models Incentives: It explicitly accounts for the cost an individual faces to manipulate specific behaviors (Björkegren et al., 2023).
Anticipates Responses: It embeds a game-theoretic model within the loss function, allowing the algorithm to predict how individuals will adjust their $x$ (features) in response to a rule $pi$ (Björkegren et al., 2023).
Prioritizes “Hard-to-Fake” Signals: The model learns to assign higher weights to features that are costly or difficult to manipulate, while de-emphasizing easily “gamed” behaviors (Björkegren et al., 2023).
Real-World Evidence: The Kenya Field Experiment
To validate their theory, the researchers conducted a large-scale field experiment in Kenya involving a smartphone-based “digital credit” app.
Experimental Design: Participants were incentivized to manipulate their phone usage (e.g., number of outgoing calls or texts) to qualify for cash rewards, mimicking the incentives of digital loans (Blumenstock et al., 2023).
Key Findings:
Predictability of Manipulation: The study found that behaviors like “outgoing communications” are significantly easier and cheaper to manipulate than “incoming communications” (Blumenstock et al., 2023).
Performance: The strategy-robust estimator produced decision rules that were stable even when fully transparent. It outperformed standard OLS models, which failed when users began strategically altering their data (Björkegren et al., 2023).
The Signaling Effect: Interestingly, the authors noted that if the ability to manipulate a feature is itself correlated with the desired outcome (e.g., highly “intelligent” people are better at gaming a specific test), the model can actually exploit this as a signal (Björkegren et al., 2023).
Why It Matters
This research challenges the “security through obscurity” approach, where algorithms are kept secret to prevent gaming. By making models robust to manipulation, policymakers can provide the “right to explanation” and transparency demanded by modern AI regulations without sacrificing the integrity of the decision-making process (Björkegren et al., 2023).
Read full paper on https://www.povertyactionlab.org/sites/default/files/research-paper/WP4644_Training-Machine-Learning-to-Anticipate-Manipulation-in-Kenya_Blumenstock-et-al_July2023.pdf